

谷歌推出了最新大模型 Gemini 2.0,并开放 Deep Research 新功能。相比之前,Gemini 2.0 在能力上有了显著提升,包括更准确的文本分类、更高效的模型训练、更丰富的数据支持等。Deep Research 新功能也提供了更深入的研究和实验平台,支持用户进行更复杂的自然语言处理任务。这些功能将有助于推动自然语言处理技术的发展和应用。
本文目录导读:
谷歌推出了最新大模型 Gemini 2.0,并同时开放 Deep Research 新功能,引发了业界广泛关注,这次更新都带来了哪些能力提升呢?
最新大模型 Gemini 2.0
Google Gemini 2.0 是谷歌最新推出的大模型,其在NLP(自然语言处理)和CV(计算机视觉)领域都取得了显著的进展,与上一代的Google Gemini 1.0相比,2.0版本在模型规模、性能和表现上都有了显著提升。
在NLP领域,Google Gemini 2.0能够更准确地理解和生成自然语言文本,使得其在语音识别、文本分类、情感分析等任务中表现更加出色,其在处理多语言、跨文化内容以及复杂语言现象时,也表现出了更强的适应性和灵活性。
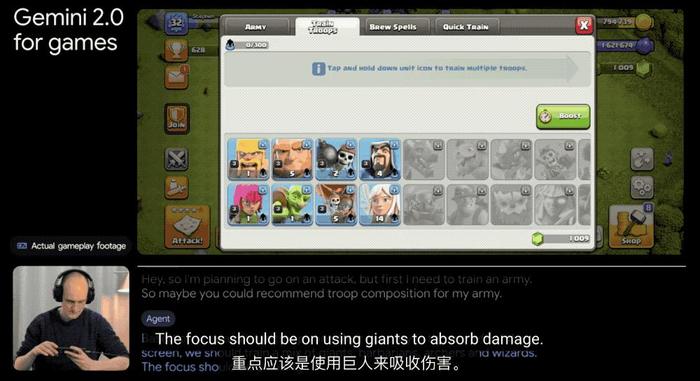
在CV领域,Google Gemini 2.0通过改进图像识别、目标检测、场景理解等关键技术,使得其在处理图像数据上更加精准和高效,其还支持多种图像格式和分辨率,使得用户能够更灵活地应用该模型进行图像处理。
Deep Research 新功能
此次更新中,谷歌还推出了Deep Research新功能,Deep Research是谷歌的一项新功能,旨在帮助开发者更深入地了解Google AI技术的最新研究成果和技术进展,通过Deep Research,开发者可以获取到Google AI技术的最新论文、数据集、API文档以及社区支持等资源,从而更快速地了解和应用Google AI技术。
Deep Research的推出,将有助于推动Google AI技术的传播和应用,通过该功能,开发者可以更加便捷地获取到Google AI技术的相关信息和资源,进而促进AI技术的普及和发展,Deep Research也将为开发者提供一个互动交流的平台,使得开发者之间可以分享经验、互相学习,共同推动AI技术的创新和发展。

能力提升
1、模型性能提升:与上一代的Google Gemini 1.0相比,2.0版本在模型性能上有了显著提升,这得益于谷歌在深度学习技术方面的不断研究和探索,以及大规模数据集的持续积累。
2、跨领域适应能力增强:Google Gemini 2.0在NLP和CV领域的表现都非常出色,同时其也支持多种语言和文化背景的数据集,这使得该模型在处理多语言、跨文化内容以及复杂语言现象时表现出了更强的适应性和灵活性。
3、图像处理技术升级:在CV领域,Google Gemini 2.0通过改进图像识别、目标检测、场景理解等关键技术,使得其在处理图像数据上更加精准和高效,其还支持多种图像格式和分辨率,使得用户能够更灵活地应用该模型进行图像处理。

4、获取Google AI技术资源更便捷:通过Deep Research功能,开发者可以获取到Google AI技术的最新论文、数据集、API文档以及社区支持等资源,这将有助于开发者更快速地了解和应用Google AI技术,推动AI技术的传播和发展。
谷歌推出最新大模型 Gemini 2.0以及开放Deep Research新功能,将为开发者带来更加便捷、高效的AI技术体验和应用,这也将推动AI技术的不断创新和发展,为各行各业提供更多智能化解决方案。
 鄂ICP备18002169号
鄂ICP备18002169号